Document Object ModelingPod skratkou DOM sa skrýva Document Object Modeling. Ide o objektové modelovanie dokumentu a čo to vlastne je? DOM je aplikačné programové rozhranie (API) pre platné HTML a správne štruktúrované XML. Definuje logickú štruktúru samotného dokumentu a umožňuje pristupovať a manipulovať s jednotlivými jeho časťami. ÚvodProstredníctvom DOMu môžeme pristupovať k dokumentu, modifikovať jeho štruktúru a meniť, mazať alebo pridávať jednotlivé jeho elementy. To znamená, že môžeme pracovať s čímkoľvek, čo dokument ako taký obsahuje. DOM nie je závislý na programovacom jazyku ani na platforme. Ako som spomínal, ide o objektový model v hierarchickej štruktúre. Tento koncept vychádza z prirodzenej vlastnosti XML respektíve HTML dokumentu. Pre ozrejmenie uvediem časť HTML dokumentu a jeho popis v objektovom modely.
Ako je možné vidieť na príklade, ide o jednoduchú tabuľku. Grafická reprezentácia hore uvedenej štruktúry vyzerá nasledovne. 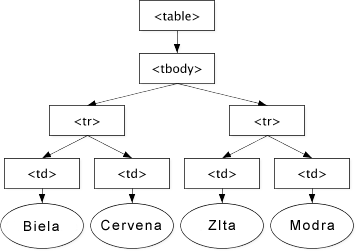
Zatiaľ sme sa na DOM pozerali ako niečo, čo abstraktné reprezentuje dokument respektíve jeho štruktúru, no DOM ako taký je implementovaný v rade skriptovacích jazykoch. Najznámejší je asi JavaScript. Existuje tiež JavaScriptu podobny jazyk z dielne Microsoftu. Ten je možné registrovať pod názvom JScript. Stretnúť sa môžeme ešte s ECMAScriptom, čo je v podstate štandardizovaný JavaScript. Všetky tieto jazyky majú jedno spoločné a to, že dokážu pracovať z DOM dokumentu, čo sa často využíva pri tvorbe takzvaného dynamického webu. Zo spomenutej množiny skriptovacích jazykov bude v príkladov použity JavaScript, no niektoré budú uvedené aj v niektorom z ďalších jazykov, ktoré som uviedol vyššie. Pri jednotlivých príkladoch potom uvediem v akom jazyku sú napísane. Na rozdiely v niektorých implementáciach, skúsim poukázať na niektorých príkladoch. Teraz uvediem príklad prace z niektorými objektami z predchádzajúceho príkladu: Tento konkrétny je uvedení v ECMAScripte:
Ako je možné vidieť z príkladu vyskytujú sa tu niektoré pojmi dobre známe z objektovo orientovaného programovania. V krátkosti by sa to dalo opísať nasledovne. Elementy ktoré v danej stromovej štruktúre vychádzajú priamo z niektorého iného elementu sa nazývajú children. Ide o pojem dobre známy z terminológie OOP. Ich predchodcovia sú ancestor. Ešte ozrejmím jednu skutočnosť. V DOM sa objekt na uzle stromu nazýva tiež NODE (uzol). Ak ma niektorý uzol viac nasledovníkov tak ako v tomto príklade, tie sa ukladajú do zoznamu, ktorý je číslovaný od 0. Medzi nimi je potom vzťah súrodenec (siblings), čo nieje momentálne až také dôležité. Číslovanie vychádza z poradia, v akom sú prvky situovane v dokumente (z hora na dol). Na tejto štruktúre je zaujímavá ešte jedna vec a to, že aj na samotný text sa pozerá ako na objekt. Každý dokument obsahuje jeden element typu dokument, jeden alebo viac elementov typu komentár, ktoré vychádzajú priamo z koreňového uzla, ktorý sa tiež nazýva ROOT . Element DOCUMENT je v koreni stromu, teda najvyššie v hierarchii. V HTML dokumente sa označuje ako <HTML> . Čo je dôležité DOM je logicky model a nehovorí nič o tom, ako majú byť vzťahy medzi jednotlivými elementmi implementovane ani o tom, že cela štruktúra musí byt reprezentovaná ako strom alebo niečo podobne. Hovorí sa iba o akejsi štruktúre, ktorú je možné reprezentovať napr. stromom. V spojení s DOM sa hovorí ešte o jednej dôležitej vlastnosti a to, že ak sú na reprezentáciu dokumentu použite dve rôzne implementácie DOMu výsledkom bude ta istá štruktúra. Treba si uvedomiť ešte jednu dôležitú vec a to, že diagram nereprezentuje dátovú štruktúru ale jednotlivé objekty. Teda ak by sme mali stručne zhrnúť, DOM definuje:
Architektúra DOMŠtandard DOM je v súčastnosti vo verzii 3 čo sa tiež označuje „LEVEL 3 DOM“. A prešiel postupným vývojom až od verzie označovanej ako LEVEL 1. Zaklad bol položený vo verzi 0, ale štandartizacia prišla až z verziou 1. Štandard každej úrovne sa skladá z niekoľkých modulov. Napr. „DOM LEVEL 1“ sa skladá z modulu CORE a HTML. Modul CORE definuje sadu základných, tiež označovaných fundamentals nízkoúrovňových rozhraní, ktorými môžeme reprezentovať akýkoľvek štruktúrovaný dokument. Toto je základ pre každú implementáciu dom dokumentu. Okrem toho obsahuje i rozšírenú implementáciu pre XML dokument. Tu nemusí obsahovať implementácia pristupujúca napr. výlučne iba k HTML dokumentu. To iste platí aj pre iné implementácie. Rozdelenie DOM do modulov môžeme vidieť na nasledujúcom grafe, kde je znázornené rozdelenie DOM LEVEL verzia 3. 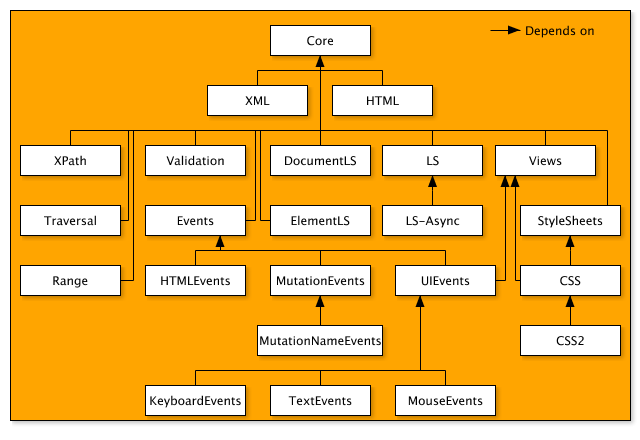
Implementácia DOMu teda musí zahŕňať jednu alebo viac modulov v závislostí od príslušného nasadenia. Napríklad v prehliadačoch je veľmi dobre implementovaný modul, ktorý obsluhuje udalosti z myší a na druhej strane tento modul nemusí byt implementovaný v prípade nasadenia dokumentu v serverovskej aplikácii, čo bolo koniec koncov uvedene už vyššie. Treba podotknúť, že DOM ako taký sa stále vyvíja a niektoré jeho časti ešte niesu v konečnej fáze História DOMDOM sa vo svojej ranej fáze nachádzal v prehliadačoch Netscape Navigator verzia 3 (NN3) a umožňoval pristupovať k niektorým prvkom dokumentu ako boli forms, images, links a anchors prostredníctvom JavaScriptu. Tento objektový model bol známy pod označením “LEVEL 0 DOM”. Využíval ho i prehliadač od Microsoftu Internet Exploreru 3 (MIE3) Ďalšia vývojová verzia tohto objektového modelu prišla s novou verziou prehliadačov a to NN 4 a MIE4. Priniesla množstvo nových prvkov a značne rozšírila možnosti nad starými, no vniesla do danej oblasti i mierne odlišnosti čo sa tyká nasadenia v jednotlivých prehliadačoch. Ako to už býva, išlo o menšie odlišnosti v riešení zo stranu microsoftu, a to konkrétne v implementácii v Scriptovacom jazyku ktorý Microsoft vyvinul ako odozvu na JavaScript. Spomínaným jazykom je JScript. Tým pribudol na poly scriptovacich jazykov ďalší hráč. Navyše ako to už býva, ide o riešenie primárne určene pre MIE. Microsoft v súvislosti z IE4 hovorí o tzv. „DHTML DOM“. Tato verzia plne kompletnú štruktúru HTML dokumentu a umožňuje prehliadačom, ktoré ho podporujú plne pristupovať k všetkým tagom ich atribútom a hodnotám a to s vysokým stupňom konzistencie medzi HTML značkami, metódami a vlastnosťami. Do tejto neprehľadnosti vniesla svetlo W3C, kde bol tento štandard presne definovaný a pri jeho dodržiavaní by nemal byt problém napísať fungujúci script využívajúci DOM pre akýkoľvek prehliadač, i keď s istými obmedzeniami. Miera využitia DOMu závisí prevažne na interpretačnej schopnosti prostredia v ktorom je implementovaný. Na záver ešte uvediem tabuľku, kde je prehľad všetkých metód a vlastnosti a to, do akej miery sú podporované jednotlivými prehliadačmi. Použil som tabuľku od Jakuba Havela, ktorý sa DOM zaoberal na stránkach servera žive.
V nasledujúcej tabuľkej je v percentách vyjadrená miera podpory jednotlivých verzii DOM pre prehliadače Mozilla a IE 6.
Navyše Mozilla obsahuje DOM inspektor, ktorý umožnuje zobraziť nie len objektový model stránky, ale aj samotného prehliadača. Ten je totiž vytvorený v tzv. XUL, ktorý vychádza priamo z XML. Mimo iné je jeho súčasťou i JS console a debugger. PríkladyPre správne predvedenie príkladov bude vhodné použiť niektorý z prehliadačov, ktoré v širšej miere podporujú implementácie DOMu. Ja osobne som sa rozhodol pre Mozillu FireFox 1.0. Príklady som skúšal i v prehliadačoch IE 6 a Opere 7, ktorú som mal nainštalovanú už skôr. Musím skonštatovať, že najhoršie skončil práve IE 6, kde funguje iba príklad 2. Skúsim bližšie opísať o čo ide v prvom príklade. V podstate je tento príklad ukážkou implementácie DOMu, v ktorej sa vracia určitý objekt dokumentu a to na základe jeho jednoznačnej identifikácie, ktorá sa v tomto prípade zabezpečí použitím položky id v atribútoch tagu. Cely predpis pritom vyzerá nasledovne: < DIV id="nazov_položky" > Keď máme takto identifikovaný objekt dokumentu, možeme napísať funkciu, ktorá ho vráti na základe jeho identifikácie. Cela funkcia bude vyzerať následovne:
Funkcia objGet pracuje dvojakým spôsobom a to, že buď vracia objekt na základe jeho id čo je situácia, ktorú som opísal vyššie, alebo v prípade, že mu pošleme ako parameter už konkrétny objekt tak ako výsledok vráti ten. Prvý prípad je zachytený v druhom riadku a druhy v prvom. Predposledne dva nam opisujú jednotlivé situácie pre prehliadače NN a IE, kde sa prístup k objektom z ich spoločného uložišťa odlišuje v syntaxe samotnej implementácie. V prípade IE sú všetky objekty dokumentu uložené v document.all.konkretny_objekt a v prípade NN v objekte document.ids.konkretny_objekt. V prípade že taký objekt nieje nájdený, je návratová hodnota NULL. Viac už v konkrétnom príklade.
Objekty respektíve inštancie príslušných tried, ako ste si mohli všimnúť, nieje nutné vytvárať. Tie totiž vytvorí samotný prehliadač pri načítaní stránky. Čo sa týka ostatných dvoch príkladov, tam stačí iba spomenúť, že pri práci so štýlmi objektu je nutné, aby mal nejaké definované. Tieto príklady sú zamerané práve na prácu so štýlmi objektov, čo je len ďalšie z množstva využití DOM pri tvorbe dynamických stránok. LinkyReferenčná príručka k DOM Oficiálna stránka DOM na W3C Stranky o DOM na servery Zive A ešte niečo na servery Webtip |
|||||||