CUDA
GP-what?
prezentacia- CPU core : freq * IPC ~ 21Gflop/s
- CPU : 0.14Tflop/s, RAM access <60 GB/s
- GPU : 5.12Tflop/s, RAM access ~336 GB/s
Hints
- Ubuntu 22.04
- NVIDIA CUDA 11.4
Pre-requisities
- CUDA device : NVIDIA GPU
- driver,kniznica
Jadro
- Include cuda.h na overenie hlavickoveho suboru
- volanie nejakej cuda-prefixovanej metody na overenie linkovania
Code
#include <cuda.h>
#include <cuda_runtime.h>
#include <stdio.h>
void probe(){
int rv,devices;
rv = cudaGetDeviceCount(&devices);
printf("[%d] Devices: %d\n",rv,devices);
}
int main(){
probe();
}
Kompilacia
nvcc -arch=sm_35 -std=c++11 -x cu main.cpp -o main
alebo
nvcc -D_FORCE_INLINES -m64 -O3 -arch=sm_35 -std=c++11 --compiler-options -fno-strict-aliasing -use_fast_math --ptxas-options=-v -x cu main.cpp -o main
- Error
- cuda.h not found
- undefined reference to cudaGetDeviceCount'
Exec
./main
[38] Devices: 0
curun req 2 ./main
[0] Devices: 2
Zariadenia
V systeme moze byt naraz viac CUDA zariadeni.Code
#include <cuda.h>
#include <cuda_runtime.h>
#include <stdio.h>
void probe(){
int rv,devices;
cudaDeviceProp prop;
rv = cudaGetDeviceCount(&devices);
printf("[%d] Devices: %d\n",rv,devices);
for(int i=0;i<devices;i++){
cudaGetDeviceProperties(&prop, i);
printf("[%i] Name: %s\n",i,prop.name);
printf(" PCI : %d:%d:%d\n",prop.pciBusID,prop.pciDomainID,prop.pciDeviceID);
printf(" Ver : %d.%d\n",prop.major,prop.minor);
printf(" Freq: %.2f MHz\n",prop.clockRate/1000.0);
printf(" MEM : %lu MB\n",prop.totalGlobalMem/(1024*1024));
}
}
int main(){
probe();
}
./main
[0] Devices: 2
[0] Name: GeForce GTX TITAN Black
PCI : 5:0:0
Ver : 3.5
Freq: 980.00 MHz
MEM : 6079 MB
[1] Name: Quadro K4000
PCI : 6:0:0
Ver : 3.0
Freq: 810.50 MHz
MEM : 3014 MB
Prvy program - Vektor * skalar
Code
#include <cuda.h>
#include <cuda_runtime.h>
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
#include <cmath>
#include <algorithm>
#include <chrono>
typedef unsigned int uint;
#define DEVICE 0
#ifdef DOUBLE_PRECISION
#define FLOATING double
#define ABS fabs
#define SIN sin
#define COS cos
#define SICO sincos
#else
#define FLOATING float
#define ABS fabsf
#define SIN sinf
#define COS cosf
#define SICO sincosf
#endif
#define SOF sizeof(FLOATING)
#define H2D cudaMemcpyHostToDevice
#define D2D cudaMemcpyDeviceToDevice
#define D2H cudaMemcpyDeviceToHost
#define CUDAEXITONERROR(s) {cudaDeviceSynchronize();cudaError err;if ((err=cudaGetLastError()) != cudaSuccess) {printf("CUDA error:%s\n%s", s,cudaGetErrorString(err));return;}}
using namespace std;
double diff(FLOATING *a,FLOATING *b,uint size){
FLOATING x,iv;
double rv=0;
volatile FLOATING tmp;
for(uint i=0;i<size;i++){
x = a[i];
tmp=x; if ((x!=tmp)|| (tmp==x && (tmp-x)!=0)) tmp=0;
iv=tmp;
x = b[i];
tmp=x; if ((x!=tmp)|| (tmp==x && (tmp-x)!=0)) tmp=0;
iv-=tmp;
rv += ABS(iv);
}
return rv;
}
class Ticker{
private:
FLOATING elapsed_ms;
chrono::steady_clock::time_point tp_prev;
chrono::steady_clock::time_point tp_now;
public:
Ticker():tp_prev(chrono::steady_clock::now()){};
void tick(const char* txt=nullptr){
tp_now = chrono::steady_clock::now();
if (txt != nullptr){
elapsed_ms = chrono::duration_cast<chrono::microseconds>(tp_now - tp_prev).count()/1000.0;
printf("[I][%8.2fms]:%s\n",elapsed_ms,txt);
}
tp_prev = tp_now;
}
};
__global__
void kernel_mul(FLOATING *src,FLOATING *tgt,uint size,FLOATING factor){
const uint numThreads = blockDim.x * gridDim.x;
for (uint i = blockIdx.x * blockDim.x + threadIdx.x; i < size; i += numThreads){
tgt[i] = src[i]*factor;
}
}
void d_mul(FLOATING *h_src,FLOATING fac,FLOATING *h_tgt,uint size){
cudaSetDevice(DEVICE);
FLOATING *d_src,*d_tgt;
Ticker tick;
cudaMalloc((void**)&d_src, SOF*size);
cudaMalloc((void**)&d_tgt, SOF*size);
cudaMemcpy(d_src,h_src,size*SOF,H2D);
tick.tick();
kernel_mul<<<512,512>>>(d_src,d_tgt,size,fac);
cudaDeviceSynchronize();
tick.tick("Exec");
cudaMemcpy(h_tgt,d_tgt,size*SOF,D2H);
cudaFree(d_src);
cudaFree(d_tgt);
}
void mul(){
Ticker tick;
uint size=64*1024*1024;
FLOATING *a,*dev,*host,fac,rv;
fac = 13.37;
a = new FLOATING[size];
dev = new FLOATING[size];
host = new FLOATING[size];
srand(time(nullptr));
tick.tick();
for(uint i=0;i<size;i++)
a[i]=(rand()%87355)/87355.0;
tick.tick("Gen");
for(uint i=0;i<size;i++)
host[i]=a[i]*fac;
tick.tick("Host");
d_mul(a,fac,dev,size);
tick.tick("CUDA");
rv = diff(host,dev,size);
tick.tick("Check");
printf("Diff : %f | %e\n",rv,rv/size);
delete a;
delete host;
delete dev;
}
int main(){
mul();
}
./main
[I][ 1327.04ms]:Gen
[I][ 425.36ms]:Host
[I][ 2.84ms]:Exec
[I][ 576.39ms]:CUDA
[I][ 1513.19ms]:Check
Diff : 0.000000 | 0.000000e+00
-DDOUBLE_PRECISION
./main
[I][ 1302.76ms]:Gen
[I][ 502.15ms]:Host
[I][ 5.05ms]:Exec
[I][ 841.00ms]:CUDA
[I][ 1267.17ms]:Check
Diff : 0.000000 | 0.000000e+00
Architektura
Processing flow
Processing grid
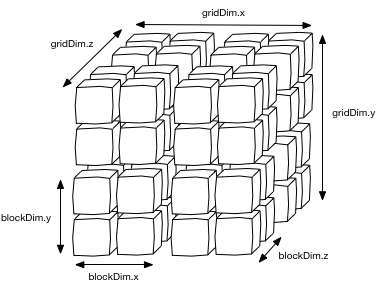
Execution

Precision (IEEE 754)
GeForce 7xx
FP64:FP32
float: 24E82 (16ME127)
double: 53E112
CUDA math
Porovnanie schopnosti roznych generacii GPU
Zadania: [Odovzdajte okomentovane riesenie uloh 7-9]
- Ziskajte pristup ku kontu studentX , zmente heslo (prikaz passwd) a vytvorte subor obsahujuci Vase meno
[vnutri skolskej siete] ssh studentX@158.197.31.56 -p 222
spustenie programu cez curun ./main - Vyskusajte vplyv prepinaca -O3 na cas behu vypoctu na CPU
- Vyskusajte vplyv prepinaca -DDOUBLE_PRECISION na cas behu vypoctu na CPU a GPU
- Vyskusajte vplyv pouzitia cudaMallocHost((void**)&d_a,SOF*size); namiesto a=new FLOATING[size]; a cudaFreeHost(d_a); namiesto delete a; (ditto pole device)
- Vyskusajte vplyv pouzitia zlozitejsej funkcie (SIN(src[i])+COS(src[i]))*factor na cas behu vypoctu na GPU, prip. optimalizacie, napr cachovanie src[i] do premennej a SICOVyskusajte vplyv prepinaca -use_fast_math na cas behu vypoctu na GPU (pri sin+cos)
- [1b] Upravte program tak, aby pocital Hadamardov sucin (po elementoch) 2 vektorov (c[i]=a[i]*b[i])[1b] Upravte predchadzajuci program a optimalizujte kod na pocitanie funkcie:
if (b[i]>0.5) c[i]=SIN(a[i])*COS(b[i]);else c[i]=COS(a[i])*SIN(b[i]); - [1b] Najdite optimalnu velkost bloku a gridu (povodne<<<512,512>>>) pre predchadzajuci problem za pouzitia nvprof: curun nvprof ./main
Code
typedef float2 dblfloat; // .y = head, .x = tail
__host__ __device__ __forceinline__
dblfloat mul_dblfloat (dblfloat x, dblfloat y)
{
dblfloat t, z;
float sum;
t.y = x.y * y.y;
t.x = fmaf (x.y, y.y, -t.y);
t.x = fmaf (x.x, y.x, t.x);
t.x = fmaf (x.y, y.x, t.x);
t.x = fmaf (x.x, y.y, t.x);
/* normalize result */
sum = t.y + t.x;
z.x = (t.y - sum) + t.x;
z.y = sum;
return z;
}
Sucet pola
Predchadzajuci priklad bol zamerany na zakladne aspekty programovania v CUDE a riesil problem natolko jednoduchy (embarassingly parallel), ze sme boli limitovani hlavne pamatovou priepustnostou.Na tejto ulohe, s ktorou sa uz stretavame aj v realnom svete, si ukazeme niektore pokrocilejsie metody.
Strata presnosti
Ideme scitavat desatinne cisla. Na jednej strane chceme ukazat vypoctovy vykon, ktory sa prejavi hlavne na velkych vstupoch, ked amortizujeme prenos dat a reziu. Na druhej strane ak scitame velke mnozstvo cisel do spolocneho akumulatora, rychlo sa stane ze pricitanim dalsej hodnoty sa kvoli obmedzenej presnosti uz akumulator nepohne (1.234567e6 + 0.1 = 1.234567e6) a teda hodnota akumulatora na konci reprezentuje sucet len casti vstupu.Ak viem priblizne rozsah vstupu a presnost datoveho typu, mozem problem oddialit napriklad pouzitim viacerych vyvazenych akumulatorov a tie nakoniec scitat.
technicka poznamka
V nasledujucich ukazkach vyskusame viacero pristupov k rieseniu ulohy a chceme porovnat ich presnost a rychlost.Samotny beh jednotlivych pristupov sa casto lisi len kernelmi a parametrami volania, tak si usetrime cas a zavedieme univerzalnu funkciu add_uni a jednotlive pristupy jej budeme dodavat ako smerniky na funkciu d_add_xyz
Atomicky sucet
Ide o paralelizaciu klasickeho sekvencneho pristupu:- Vezmi hodnotu
- Vezmi aktualny sucet (hodnotu akumulatora)
- Prirad do akumulatora sucet hodnot z 1 a 2
- Kedze akumulator je zdielany, jedno vlakno moze byt na kroku 2 ked ine vlakno vykona vsetky 3 kroky, cim zneplatni hodnotu akumulatora ktoru ma prve vlakno nacitanu
- Akumulator je nadmerne vytazeny
Code
#include <cuda.h>
#include <cuda_runtime.h>
#include <stdio.h>
#include <time.h>
#include <stdlib.h>
#include <cmath>
#include <algorithm>
#include <chrono>
typedef unsigned int uint;
#define DEVICE 0
#ifdef DOUBLE_PRECISION
#define FLOATING double
#define ABS fabs
#define SIN sin
#define COS cos
#define SICO sincos
#define ATOMADD atomicAddDouble
#else
#define FLOATING float
#define ABS fabsf
#define SIN sinf
#define COS cosf
#define SICO sincosf
#define ATOMADD atomicAdd
#endif
#define SOF sizeof(FLOATING)
#define H2D cudaMemcpyHostToDevice
#define D2D cudaMemcpyDeviceToDevice
#define D2H cudaMemcpyDeviceToHost
#define CUDAEXITONERROR(s) {cudaDeviceSynchronize();cudaError err;if ((err=cudaGetLastError()) != cudaSuccess) {printf("CUDA error:%s\n%s", s,cudaGetErrorString(err));return;}}
using namespace std;
const uint size = 8* 1024 *1024;
FLOATING a[size], dev[1], host[1024], rv;
double diff(FLOATING *a,FLOATING *b,uint size){
FLOATING x,iv;
double rv=0;
volatile FLOATING tmp;
for(uint i=0;i<size;i++){
x = a[i];
tmp=x; if ((x!=tmp)|| (tmp==x && (tmp-x)!=0)) tmp=0;
iv=tmp;
x = b[i];
tmp=x; if ((x!=tmp)|| (tmp==x && (tmp-x)!=0)) tmp=0;
iv-=tmp;
rv += ABS(iv);
}
return rv;
}
#if __CUDA_ARCH__ < 600
__device__ double atomicAddDouble(double* address, double val) {
unsigned long long int* address_as_ull = (unsigned long long int*)address;
unsigned long long int old = *address_as_ull, assumed;
do {
assumed = old;
old = atomicCAS(address_as_ull, assumed, __double_as_longlong(val + __longlong_as_double(assumed)));
// Note: uses integer comparison to avoid hang in case of NaN (since NaN != NaN)
} while (assumed != old);
return __longlong_as_double(old);
}
#endif
class Ticker{
private:
FLOATING elapsed_ms;
chrono::steady_clock::time_point tp_prev;
chrono::steady_clock::time_point tp_now;
public:
Ticker():tp_prev(chrono::steady_clock::now()){};
void tick(const char* txt=nullptr){
tp_now = chrono::steady_clock::now();
if (txt != nullptr){
elapsed_ms = chrono::duration_cast<chrono::microseconds>(tp_now - tp_prev).count()/1000.0;
printf("[I][%8.2fms]:%s\n",elapsed_ms,txt);
}
tp_prev = tp_now;
}
};
__global__
void kernel_add_atomic(FLOATING *src, FLOATING *tgt, uint size) {
const uint numThreads = blockDim.x * gridDim.x;
for (uint i = blockIdx.x * blockDim.x + threadIdx.x; i < size; i += numThreads) {
ATOMADD(&tgt[0], src[i]);
}
}
void d_add_atomic(FLOATING *h_src, FLOATING *h_tgt, uint size) {
cudaSetDevice(DEVICE);
FLOATING *d_src, *d_tgt;
Ticker tick;
cudaMalloc((void**)&d_src, SOF*size);
cudaMalloc((void**)&d_tgt, SOF);
cudaMemcpy(d_src, h_src, size*SOF, H2D);
tick.tick();
kernel_add_atomic << <512 , 512 >> >(d_src, d_tgt, size);
cudaDeviceSynchronize();
tick.tick("Exec");
cudaMemcpy(h_tgt, d_tgt, SOF, D2H);
cudaFree(d_src);
cudaFree(d_tgt);
}
void add_uni(void (*the_f)(FLOATING*,FLOATING*,uint))
{
Ticker tick;
srand(time(nullptr));
tick.tick();
for (uint i = 0; i < size; i++)
a[i] = (rand() % 87355) / 87355.0;
tick.tick("Gen");
memset(host,0,sizeof(host));
for (uint i = 0; i < size; i++)
host[i%1024] += a[i];
for (uint i = 1;i < 1024; i++)
host[0] += host[i];
tick.tick("Host");
dev[0]=0;
the_f(a, dev, size);
tick.tick("CUDA");
rv = ABS(dev[0] - host[0]);
tick.tick("Check");
printf("Host: %f Device: %f Diff : %f\n", host[0], dev[0], rv);
}
int main() {
printf("atomic sucet\n");add_uni(d_add_atomic);printf("\n");
}
Kooperacia a konkurencia
Existuje niektolko pristupov k paralelnemu scitaniu prvkov. Ako skoro vzdy, aj tu vynika divide and conquer.Myslienka je taka, ze sucet prebieha v niekolkych kolach a vzdy scitavame medzivysledky z predchadzajuceho kola. (predpokladajme velkost je mocnina 2)
V tomto pripade konkretne vlakno vezme jemu prisluchajuci prvok v druhej polovici pola a prirata ho k svojmu prvku v prvej polovici. V dalsom kroku potom riesime ten isty problem, ale len s prvou polovicou, pouzitim len polovice vlakien.
Jeden krok moze byt vhodne oparametrovanym volanim nejakej funckie, za cenu rezie opakovaneho spustania kernelov. (spravne, ale 'pomale')
Alebo mozeme kroky spustat v cykle priamo v kerneli, pouzitim mechanizmu synchronizacie vlakien. (nespravne, lebo ...)
Code
__global__
void kernel_add_global(FLOATING *src, FLOATING *tgt, uint size) {
uint myIdx = blockIdx.x * blockDim.x + threadIdx.x;
for (uint i = size / 2; i > 0; i/=2)
{
if (myIdx < i)
src[myIdx] += src[myIdx + i];
__syncthreads();
}
if (myIdx == 0)
*tgt = src[0];
}
void d_add_global(FLOATING *h_src, FLOATING *h_tgt, uint size) {
cudaSetDevice(DEVICE);
FLOATING *d_src, *d_tgt;
Ticker tick;
cudaMalloc((void**)&d_src, SOF*size);
cudaMalloc((void**)&d_tgt, SOF);
cudaMemcpy(d_src, h_src, size*SOF, H2D);
int threadsPerBlock = 1024;
uint n_blocks = std::min((size + threadsPerBlock - 1) / threadsPerBlock, uint(1024));
tick.tick();
kernel_add_global << <n_blocks, threadsPerBlock >> >(d_src, d_tgt, size);
cudaDeviceSynchronize();
tick.tick("Exec");
cudaMemcpy(h_tgt, d_tgt, SOF, D2H);
cudaFree(d_src);
cudaFree(d_tgt);
}
int main() {
printf("atomic sucet\n");add_uni(d_add_atomic);printf("\n");
printf("add_global\n"); add_uni(d_add_global);printf("\n");
}
Synchronizacia vlakien
... funkcia __syncthreads() funguje v 'device' kode (v kerneli) a synchronizuje jednotlive vlakna bloku.Jednotlive prikazy v kerneli sa vykonavaju naraz vo viacerych vlaknach (SIMT - single instruction multiple threads) tvoriacich tzv. warp, ktory je dielikom bloku (napr. warp je 32, blok 1024 a teda je zlozeny z 32 warpov)
Warpy su teda implicitne synchronizovane a pomocou __syncthreads vieme synchronizivat aj vlakna bloku, no nie bloky medzi sebou!
Toto riesenie teda nefunguje, lebo sa vlakna nesynchronizuju globalne, ako by sme potrebovali podla popisu riesenia. Princip ale funguje a dalsie pokusy ho budu tiez pouzivat ... a vyriesia synchronizaciu inac
Zdielana pamat
Dalsim dolezitym mechanizmom CUDY (vo vseobecnosti GPU) je pamat zdielana medzi vlaknami threadu.V predchadzajucej ukazke ukladame medzisucty spat do globalnej pamate GPU (konkretne spat do povodneho pola), co je casovo velmi narocne (teraflopy vypoctoveho vykonu vs stovky GB/s). Teraz budeme riesit sucet v dvoch krokoch:
- Najst sucet vsetkych prvkov prisluchajucich jednotlivym blokom a ulozit do medzivysledku
- Znova pustit tu istu funkciu, ale na medzivysledku (radovo mensie pole) a len s 1 blokom
__shared__
Pre pouzitie zdielanej pamate pouzijeme jedno z nasledujucich:- __shared__ FLOATING sdata[velkost]; ... pri statickej velkosti, znamej pocas kompilacie
- extern __shared__ FLOATING sdata[]; ... pre dynamicku zdielanu pamat, velkost sa konfiguruje vo volani kernela
kernel<< < gdim, bdim, shared_memory_in_bytes >> >
u dynamickej deklaracii vieme pouzit len jednu premennu pre pamat, v pripade potreby viacerych musime sami riesit pakovanie (see SM a SMD u nasobenia matic)
- Kazde vlakno vypocita sucet jemu prisluchajucich policok a ulozi ho do svojej casti zdielanej pamate
Tento kod taktiez ukazuje pretazovanie vlakien, kedy jedno vlakno ma na starosti vacsie mnozstvo policok. ... vsetky vlakna bloku maju rovnocenny pristup k zdielanej pamati, takze to nie je exkluzivne jeho cast, ale z hladiska efektivity je lepsie ked nemusime riesit konflikty medzi vlaknami a kym sa da, kazde vlakno hrabe na svojom piesocku - Synchronizacia ... cakame kym zdielana pamat obsahuje korektne hodnoty
- Aplikujeme metodu divide&conquer ako v predchadzajucom priklade
tentokrat ale korektne - Na konci reprezentant bloku (napr. vlakno 0) ulozi sucet za blok na unikatnu poziciu (index bloku) medzivysledku
Code
__global__
void kernel_add_shared(FLOATING *src, FLOATING* tgt, uint size)
{
uint tIdx = threadIdx.x;
extern __shared__ FLOATING sdata[];
sdata[tIdx] = 0;
for (uint i = blockIdx.x * blockDim.x + threadIdx.x; i < size; i += blockDim.x * gridDim.x)
{
sdata[tIdx] += src[i];
}
// make sure entire block is loaded!
__syncthreads();
for (uint i = blockDim.x / 2; i > 0; i /= 2)
{
if (tIdx < i)
sdata[tIdx] += sdata[tIdx + i];
__syncthreads(); // make sure all adds at one stage are done!
}
if (tIdx == 0)
tgt[blockIdx.x] = sdata[0];
}
void d_add_shared(FLOATING *h_src, FLOATING *h_tgt, uint size) {
cudaSetDevice(DEVICE);
FLOATING *d_src, *d_tgt;
Ticker tick;
cudaMalloc((void**)&d_src, SOF*size);
cudaMalloc((void**)&d_tgt, SOF);
cudaMemcpy(d_src, h_src, size*SOF, H2D);
uint threadsPerBlock = 1024;
uint n_blocks = std::min((size + threadsPerBlock - 1) / threadsPerBlock, uint(1024));
FLOATING *d_intermediate;
cudaMalloc((void**)&d_intermediate, SOF*n_blocks);
tick.tick();
kernel_add_shared << <n_blocks, threadsPerBlock, SOF * threadsPerBlock >> >(d_src, d_intermediate, size);
kernel_add_shared << <1, n_blocks, SOF * n_blocks >> >(d_intermediate, d_tgt, n_blocks);
cudaDeviceSynchronize();
tick.tick("Exec");
cudaMemcpy(h_tgt, d_tgt, SOF, D2H);
cudaFree(d_src);
cudaFree(d_tgt);
cudaFree(d_intermediate);
}
int main() {
printf("atomic sucet\n");add_uni(d_add_atomic);printf("\n");
printf("shared sucet\n");add_uni(d_add_shared);printf("\n");
printf("add_global\n"); add_uni(d_add_global);printf("\n");
}
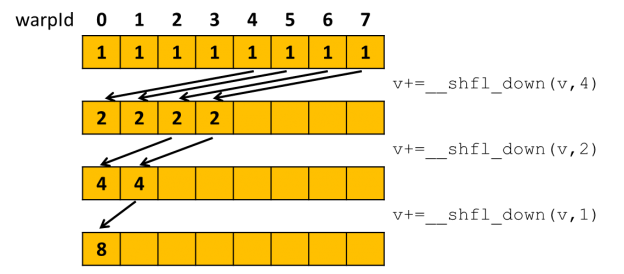
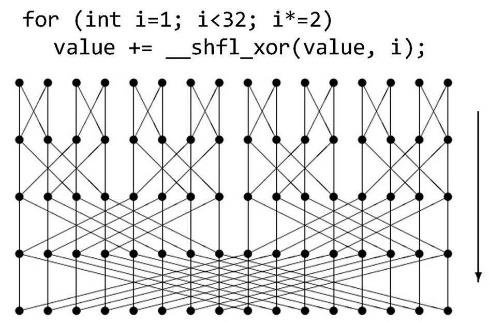
Shuffle
Inym sposobom ako vedia vlakna medzi sebou komunikovat je shuffle.Pomocou shuffle si vedia jednotlive vlakna vzajomne podsunut obsah registrov (lokalne premenne) v ramci warpu.
V tomto pripade chceme len redukovat pole, staci pouzit jednosmerny shuffle (napr _shfl_down), ak by sme ale potrebovali vzajomne vymenit informaciu medzi vlaknami, mozeme pouzit napr. _shfl_xor
{kind=link}
{kind=link}
- Zavolame redukciu v ramci warpu
- Reprezentant warpu (vlakna su priradene k warpom sekvencne, prvy zacina na indexe 0, druhy na 32, ... pre warp velkosti 32) ulozi sucet do zdielanej pamate
- Redukcia v ramci warpu nad hodnotami v zdielanej pamati
- Reprezentant (nulteho) warpu ulozi medzivysledok za cely blok, pricom medzivysledky sa scitaju v dalsom behu ako predtym
Code
FLOATING warpReduceSum(FLOATING val) {
for (uint offset = warpSize / 2; offset > 0; offset /= 2)
val += __shfl_down_sync(-1, val, offset);
//printf("hodnota z warpShuffle = %f \n", val);
return val;
}
__inline__ __device__
FLOATING blockReduceSum(FLOATING val)
{
__shared__ FLOATING shared[32]; // Shared mem for 32 partial sums
uint lane = threadIdx.x % warpSize;
uint wid = threadIdx.x / warpSize;
// Each warp performs partial reduction
val = warpReduceSum(val);
// Write reduced value to shared memory
if (lane == 0) shared[wid] = val;
// Wait for all partial reductions
__syncthreads();
//read from shared memory only if that warp existed
val = (threadIdx.x < blockDim.x / warpSize) ? shared[lane] : 0;
if (wid == 0) val = warpReduceSum(val); //Final reduce within first warp
return val;
}
__global__ void kernel_add_shuffle_block(FLOATING *src, FLOATING* tgt, uint size) {
FLOATING sum = 0;
//reduce multiple elements per thread
for (uint i = blockIdx.x * blockDim.x + threadIdx.x; i < size; i += blockDim.x * gridDim.x)
{
sum += src[i];
}
sum = blockReduceSum(sum);
if (threadIdx.x == 0)
tgt[blockIdx.x] = sum;
}
void d_add_shuffle_block(FLOATING *h_src, FLOATING *h_tgt, uint size) {
cudaSetDevice(DEVICE);
FLOATING *d_src, *d_tgt;
Ticker tick;
cudaMalloc((void**)&d_src, SOF*size);
cudaMalloc((void**)&d_tgt, SOF);
cudaMemcpy(d_src, h_src, size*SOF, H2D);
uint threadsPerBlock = 1024;
uint n_blocks = std::min((size + threadsPerBlock - 1) / threadsPerBlock, uint(1024));
FLOATING *d_intermediate;
cudaMalloc((void**)&d_intermediate, SOF*n_blocks);
tick.tick();
kernel_add_shuffle_block << <n_blocks, threadsPerBlock >> >(d_src, d_intermediate, size);
kernel_add_shuffle_block << <1, 1024 >> >(d_intermediate, d_tgt, n_blocks);
cudaDeviceSynchronize();
tick.tick("Exec");
cudaMemcpy(h_tgt, d_tgt, SOF, D2H);
cudaFree(d_src);
cudaFree(d_tgt);
cudaFree(d_intermediate);
}
int main() {
printf("atomic sucet\n");add_uni(d_add_atomic);printf("\n");
printf("shared sucet\n");add_uni(d_add_shared);printf("\n");
printf("warp shuffle sucet\n");add_uni(d_add_shuffle_block);printf("\n");
printf("add_global\n"); add_uni(d_add_global);printf("\n");
}
Kombinacia shuffle a atomicky sucet
Namiesto scitavania warpov cez zdielanu pamat mozeme napriklad pouzit atomicky sucet (kernel_add_shuffle_warp_atomic)V tomto pripade sme pouzitim warpov zredukovali velkost vstupu (a pravdepodobnost kolizii) natolko, ze sa oplati vyskusat ci atomic nebude rychlejsi ako zdielana pamat Kompletny kod z cviceni si mozete stiahnut >>>tu<<< (ak z nejakeho dovodu kod z blokov nefunguje, tento by mal)
Niektore funkcie su zamerne vypnute pri pouziti dvojitej presnosti.
=== koniec cvicenia ===
EXTRA: Matrix Multiplication

Code
__global__
void kernel_mmul(FLOATING *a,FLOATING *b,FLOATING *tgt,uint size){
uint x=blockDim.x*blockIdx.x + threadIdx.x;
uint y=blockDim.y*blockIdx.y + threadIdx.y;
uint i;
FLOATING val;
if (x<size && y<size){
val=0;
for(i=0;i<size;i++)
val += a[i+y*size] * b[x+i*size];
tgt[x+y*size]=val;
}
}
void d_mmul(FLOATING *h_a,FLOATING *h_b,FLOATING *h_tgt,uint size){
cudaSetDevice(DEVICE);
FLOATING *d_a,*d_b,*d_tgt;
Ticker tick;
dim3 gdim,bdim;
int bx=32,by=16;
cudaMalloc((void**)&d_a, SOF*size*size);
cudaMalloc((void**)&d_b, SOF*size*size);
cudaMalloc((void**)&d_tgt, SOF*size*size);
cudaMemcpy(d_a,h_a,size*size*SOF,H2D);
cudaMemcpy(d_b,h_b,size*size*SOF,H2D);
bdim = dim3(bx,by,1);
gdim = dim3((size+bx-1)/bx,(size+by-1)/by,1);
tick.tick();
kernel_mmul<<<gdim,bdim>>>(d_a,d_b,d_tgt,size);
cudaDeviceSynchronize();
tick.tick("Exec");
cudaMemcpy(h_tgt,d_tgt,size*size*SOF,D2H);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_tgt);
CUDAEXITONERROR("Done");
}
void mmul(){
Ticker tick;
uint size=1024;
FLOATING *a,*b,*dev,*host,rv,tmp;
a = new FLOATING[size*size];
b = new FLOATING[size*size];
dev = new FLOATING[size*size];
host = new FLOATING[size*size];
srand(time(nullptr));
tick.tick();
for(uint i=0;i<size*size;i++){
a[i]=(rand()%87355)/87355.0;
b[i]=(rand()%87355)/87355.0;
}
tick.tick("Gen");
for(uint x=0;x<size;x++)
for(uint y=0;y<size;y++){
tmp=0;
for(uint k=0;k<size;k++)
tmp+=a[k+y*size]*b[x+k*size];
host[x+y*size]=tmp;
}
tick.tick("Host");
d_mmul(a,b,dev,size);
tick.tick("CUDA");
rv = diff(host,dev,size*size);
tick.tick("Check");
printf("Diff : %f | %e\n",rv,rv/(size*size));
delete a;
delete b;
delete host;
delete dev;
}
int main(){
mmul();
}
./main
[I][ 58.49ms]:Gen
[I][ 9401.92ms]:Host
[I][ 13.63ms]:Exec
[I][ 341.94ms]:CUDA
[I][ 25.20ms]:Check
Diff : 7.629135 | 7.275710e-06
-DDOUBLE_PRECISION
./main
[I][ 59.34ms]:Gen
[I][ 9279.25ms]:Host
[I][ 24.06ms]:Exec
[I][ 415.43ms]:CUDA
[I][ 23.22ms]:Check
Diff : 0.000000 | 1.359871e-14
Zdielana pamat
Pri nasobeni matic nasobime riadok stlpcom (a[i][k] * b[k][j]), skusme to dekonstruovat- Riadok s riadkom: a[i][k] * b[j][k]
- Stlpec so stlpcom: a[k][i] * b[k][j]
"Nahodny" pristup do pamati je pomaly!
Code
#define TILE 32
__global__
void kernel_mmul_SM(FLOATING *a,FLOATING *b,FLOATING *tgt,uint size){
__shared__ FLOATING sha[TILE*TILE_PT];
__shared__ FLOATING shb[TILE*TILE_PT];
uint x=blockDim.x*blockIdx.x + threadIdx.x;
uint y=blockDim.y*blockIdx.y + threadIdx.y;
uint k,win;
FLOATING val=0;
for(win=0;win<size;win+=TILE){
sha[threadIdx.x+threadIdx.y*TILE_PT]=(y<size&&win+threadIdx.x<size?a[threadIdx.x+win+y*size]:0);
shb[threadIdx.x+threadIdx.y*TILE_PT]=(x<size&&win+threadIdx.y<size?b[x+(threadIdx.y+win)*size]:0);
__syncthreads();
for(k=0;k<TILE;k++)
val+=sha[k+threadIdx.y*TILE_PT]*shb[k*TILE_PT+threadIdx.x];
__syncthreads();
}
if (x<size && y<size)
tgt[x+y*size]=val;
}
void d_mmul(FLOATING *h_a,FLOATING *h_b,FLOATING *h_tgt,uint size){
cudaSetDevice(DEVICE);
FLOATING *d_a,*d_b,*d_tgt;
Ticker tick;
dim3 gdimt,bdimt;
int tile;
tile=TILE;
cudaMalloc((void**)&d_a, SOF*size*size);
cudaMalloc((void**)&d_b, SOF*size*size);
cudaMalloc((void**)&d_tgt, SOF*size*size);
cudaMemcpy(d_a,h_a,size*size*SOF,H2D);
cudaMemcpy(d_b,h_b,size*size*SOF,H2D);
bdimt = dim3(tile,tile,1);
gdimt = dim3((size+tile-1)/tile,(size+tile-1)/tile,1);
tick.tick();
kernel_mmul_SM<<<gdimt,bdimt>>>(d_a,d_b,d_tgt,size);
cudaDeviceSynchronize();
tick.tick("Exec");
cudaMemcpy(h_tgt,d_tgt,size*size*SOF,D2H);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_tgt);
CUDAEXITONERROR("Done");
}
Code
__global__
void kernel_mmul_SMD(FLOATING *a,FLOATING *b,FLOATING *tgt,uint size,uint tile){
extern __shared__ float sh[];
uint x=blockDim.x*blockIdx.x + threadIdx.x;
uint y=blockDim.y*blockIdx.y + threadIdx.y;
uint k,win;
FLOATING val=0;
for(win=0;win<size;win+=tile){
sh[threadIdx.x+threadIdx.y*tile]=(y<size&&win+threadIdx.x<size?a[threadIdx.x+win+y*size]:0);
sh[tile*tile+threadIdx.x+threadIdx.y*tile]=(x<size&&win+threadIdx.y<size?b[x+(threadIdx.y+win)*size]:0);
__syncthreads();
for(k=0;k<tile;k++)
val+=sh[k+threadIdx.y*tile]*sh[tile*tile+k*tile+threadIdx.x];
__syncthreads();
}
if (x<size && y<size)
tgt[x+y*size]=val;
}
kernel_mmul_SMD<<<gdimt,bdimt,tile*tile*2*SOF>>>(d_a,d_b,d_tgt,size,tile);